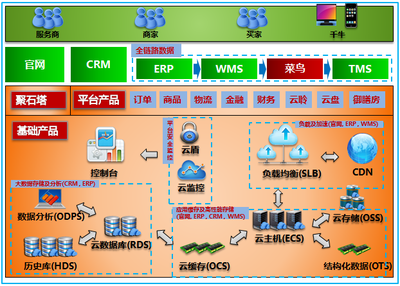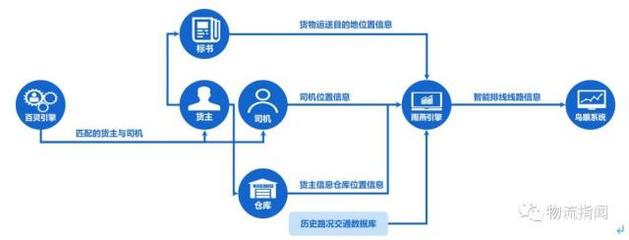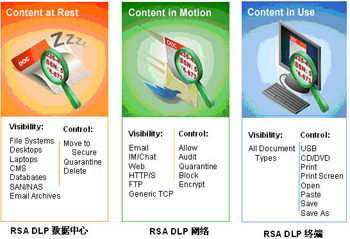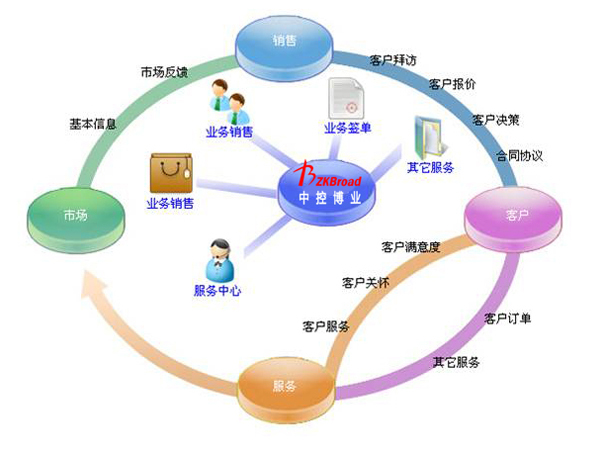
在當今數字化時代,信息服務業作為數字經濟的重要支柱,其核心概念與業務流程往往復雜且抽象。為了更直觀、高效地傳達這些概念,一套精心設計的“托管服務概念圖標集”應運而生。它不僅是視覺裝飾,更是連接技術語言與用戶理解、提升品牌專業形象與溝通效率的關鍵工具。
一、圖標集的核心價值:化繁為簡的視覺語言
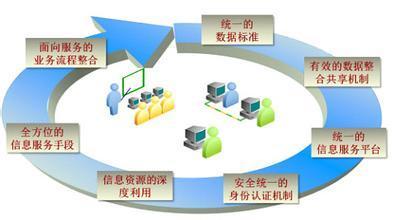
“托管服務”在信息服務業中,通常指由服務提供商全面負責客戶IT基礎設施、平臺、軟件或工作負載的運營、維護與支持。其概念涵蓋服務器托管、云服務、數據備份、網絡安全、應用運維等多個專業領域。純文字描述難免晦澀,而一套系統化的圖標集則能將這些抽象服務轉化為簡潔、統一、易識別的視覺符號。
例如:
- 服務器/數據中心圖標:常以機架式服務器或帶有網絡標志的建筑輪廓表示,象征穩定、可擴展的基礎設施托管。
- 云與連接圖標:采用飄逸的云朵圖案與交織的線條或節點,直觀體現云計算、網絡互聯與資源彈性。
- 安全盾牌與鎖圖標:代表網絡安全、數據加密與合規性保障,是托管服務中信任感的視覺基石。
- 齒輪與工具圖標:寓意持續的監控、運維、技術支持與自動化流程。
- 數據備份與恢復圖標:常用重疊的磁盤、向上的箭頭或循環符號,可視化數據保護與業務連續性服務。
這些圖標共同構建了一套視覺詞匯,使客戶、合作伙伴及內部團隊能夠快速把握服務的核心內涵與價值主張。
二、在信息服務業務中的多元應用場景
- 品牌與營銷材料:在官網、宣傳冊、演示文稿中,圖標集能迅速吸引視線,清晰勾勒服務版圖,強化“專業、可靠、技術領先”的品牌認知。
- 產品與服務介紹:在服務目錄、解決方案頁面或報價單中,圖標可以作為分類導航或視覺摘要,幫助用戶快速定位所需服務模塊,降低信息獲取門檻。
- 用戶界面(UI)與體驗(UX)設計:在客戶門戶、控制面板或監控系統中,圖標用于標識功能區域、服務狀態(如運行正常、警告、故障)或操作按鈕,提升界面的直觀性與使用效率。
- 內部培訓與文檔:幫助新員工或非技術部門人員理解復雜的服務架構與流程,是知識傳遞的視覺輔助工具。
- 行業報告與白皮書:在內容中插入概念圖標,能使數據分析、趨勢解讀更生動,增強內容的可讀性與傳播力。
三、設計原則:確保精準與一致性
一套有效的托管服務概念圖標集,其設計需遵循以下核心原則:
- 語義準確性:圖標必須準確反映其所代表的服務概念,避免歧義。設計需深入理解業務細節。
- 視覺一致性:保持統一的風格(如線性、面性、扁平化、漸變色彩)、線條粗細、比例尺度和細節層次,形成和諧的整體。
- 簡潔與可擴展性:在保證識別度的前提下力求造型簡約,并預留足夠的變體空間以適應未來服務范圍的擴展。
- 跨文化適應性:考慮到信息服務業務的全球化特性,圖標應盡量避免使用可能產生文化誤解的具象元素。
- 可訪問性:確保圖標在不同尺寸、背景色及設備上均有良好的辨識度,并考慮為關鍵圖標提供文字標簽輔助。
四、未來趨勢:動態化與智能化演進
隨著信息服務業務向更自動化、智能化的方向演進,托管服務概念圖標集也呈現出新的趨勢:
- 動態圖標與微交互:在數字界面中,圖標可以融入簡單的動畫(如旋轉的齒輪表示處理中,閃爍的盾牌表示安全掃描),以反映實時狀態或引導用戶操作。
- 與AI/數據分析融合:圖標可作為數據可視化的一部分,例如用不同顏色或填充程度的云圖標表示云資源使用率,使監控數據一目了然。
- 定制化與模塊化:企業可根據自身獨特的服務組合,對基礎圖標庫進行個性化組合與再設計,形成獨有的視覺資產。
###
總而言之,一套設計精良的“托管服務概念圖標集”是信息服務業務在激烈市場競爭中不可或缺的視覺溝通戰略資產。它將無形的技術能力轉化為有形的視覺信任,不僅提升了信息傳遞的效能,更在潛移默化中塑造著用戶對服務專業性、可靠性與前沿性的感知。在視覺主導的信息時代,投資于這樣一套圖標系統,無疑是賦能品牌、優化體驗、驅動業務增長的明智之舉。